Back
Best GPU Clouds for Computer Vision Projects (October 2025)
Best GPU Clouds for Computer Vision Projects (October 2025)
Published:
Oct 29, 2025
Last updated:
Oct 29, 2025

If you've been running any computer vision GPU projects, you know that expensive cloud setups can quickly drain your budget. But selecting the right provider with the right features can be challenging: you are either stuck with high costs and usable development tools or affordable pricing and clunky SSH connections. Thankfully, there are options that combine enterprise-grade hardware with developer-friendly pricing and smooth IDE integration.
TLDR:
Computer vision GPU training costs can be 50-80% less on specialized providers vs AWS/Google Cloud
Thunder Compute offers A100 80GB instances at $0.78/hr with VS Code integration and hardware swapping
RunPod and Vast.ai provide lower-cost options but lack reliability for long training jobs
You can scale from T4 prototyping to H100 production without rebuilding your environment
Thunder Compute delivers enterprise-grade GPUs with startup-friendly pricing and developer tools
What is Computer Vision GPU Cloud Computing?
Computer vision GPU cloud computing refers to using remote GPU-powered servers to process visual data and train AI models that can interpret images and videos. Why GPUs?
First, GPUs excel at the parallel processing required for computer vision tasks like object detection, image classification, and facial recognition.
Second, GPUs contain thousands of cores that can handle these calculations simultaneously, making them necessary for any serious computer vision project.
Finally, it's about speed. Computer vision workloads can be 10-100x faster on GPUs compared to CPUs, turning weeks of training time into hours.
As you can probably imagine, though, using those thousands of cores to handle concurrent calculations isn't cheap. That's because training a single object detection model can require processing millions of images through complex neural networks with billions of parameters.
Thankfully, cloud GPU services eliminate the need to purchase expensive hardware upfront. A high-end GPU like an A100 costs $15,000+ to buy, but you can rent one for under $1 per hour. This makes advanced computer vision accessible to startups, researchers, and individual developers who couldn't otherwise afford the infrastructure. The cloud approach also provides flexibility. You can scale from a single GPU for prototyping to multiple GPUs for production training, then scale back down when projects finish. This on-demand model perfectly matches the bursty nature of computer vision development cycles.
How We Ranked Best GPU Clouds for Computer Vision Projects
We looked at GPU cloud providers based on five key factors, focusing on real-world performance over marketing claims, that directly impact computer vision project success:
Pricing and Value. We compared hourly rates for identical GPU configurations across providers. Computer vision projects often require extended training periods, making cost control important for most teams.
Hardware Performance. We assessed available GPU types, VRAM capacity, and memory bandwidth. Computer vision models need substantial VRAM for large image batches and high-resolution processing. GPU benchmarks show major performance differences between GPU generations.
Development Experience. We tested deployment speed, IDE integration, and environment setup complexity. Computer vision workflows benefit from smooth notebook access and pre-installed frameworks like PyTorch and OpenCV.
Scalability Features. We looked at multi-GPU support, instance resizing options, and storage persistence. Computer vision projects frequently scale from single-GPU prototyping to multi-GPU production training.
Reliability and Support. We considered uptime guarantees, data persistence, and technical documentation quality. Long-running training jobs require stable infrastructure to avoid losing hours of progress.
Each provider received scores across these dimensions, weighted by importance to typical computer vision workflows. More details on choosing the right GPU for AI workloads can help inform your decision.
1. Best Overall: Thunder Compute
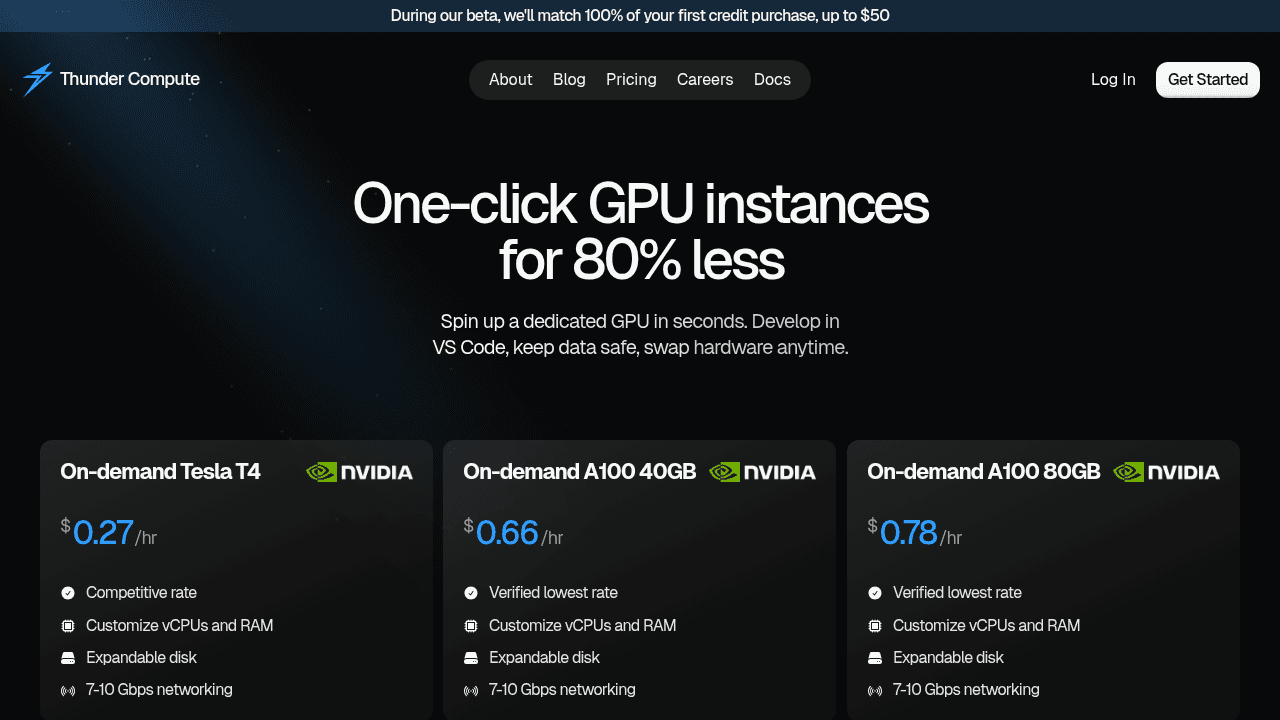
Thunder Compute delivers the most cost-effective GPU cloud solution for computer vision projects, combining enterprise-grade hardware with developer-focused features. At $0.78/hour for A100 80GB instances, Thunder Compute provides up to 80% savings compared to traditional cloud providers while offering one-click deployment and VS Code integration.
Some of Thunder Compute's key computer vision strengths include:
Hardware swapping. This feature lets you start prototyping on a T4 GPU and upgrade to an H100 for production training without losing your environment setup. The flexibility proves invaluable when scaling computer vision models from initial experiments to full dataset training.
VS Code integration. This eliminates the typical friction of remote GPU development. You can edit code, visualize training metrics, and debug computer vision pipelines directly in your familiar IDE environment.
Persistent storage. Thunder Compute's persistent storage keeps your datasets and partially trained models safe through instance restarts, preventing costly training interruptions.
From a pricing perspective, Thunder Compute offers the lowest GPU pricing in the market. Computer vision projects often require extended training periods, making this cost savings important for budget-conscious teams.
Bottom line: For computer vision developers seeking maximum performance per dollar, Thunder Compute combines the best pricing with developer-friendly features that speed up project timelines.
2. RunPod
RunPod operates a distributed cloud that provides GPU instances through a containerized approach. The service offers access to different GPU types from consumer RTX cards to enterprise A100s through per-second billing.
Some of RunPod's key computer vision features include:
Template library. RunPod's template library includes pre-configured environments for popular computer vision frameworks like PyTorch and TensorFlow.
Community cloud option. This option provides access to consumer GPUs at lower rates, which can work for smaller computer vision experiments.
Per-second billing. This billing model helps control costs during iterative development cycles common in computer vision projects. You pay only for actual compute time instead of full hours.
Some of RunPod's key limitations include:
Container-first architecture. RunPod's container-first architecture requires restructuring traditional development workflows. Computer vision projects often involve complex data pipelines and custom environments that don't translate easily to containerized deployments.
Storage persistence. This requires separate network volume attachments, adding complexity and cost. This creates friction when working with large image datasets that need reliable access across training sessions.
From a pricing perspective, while RunPod advertises competitive rates, additional fees for storage and networking can increase total costs by a large amount for data-intensive computer vision workloads.
Bottom line: RunPod works for containerized computer vision workflows but requires workflow adaptation. Teams comfortable with container orchestration may find value, but traditional development approaches face unnecessary complexity. For simpler alternatives, consider RunPod alternatives that offer more straightforward VM-based approaches.
3. Lambda Labs
Lambda Labs provides bare-metal GPU instances targeting research institutions and enterprise customers. The service focuses on high-performance hardware access with pre-configured ML environments and multi-node training features.
Some of Lambda Labs' key computer vision features include:
Dedicated hardware. Lambda Labs offers dedicated hardware without virtualization overhead, which benefits compute-intensive computer vision tasks like training large object detection models. Their pre-installed software stacks include optimized versions of PyTorch, TensorFlow, and CUDA libraries tuned for computer vision workloads.
Multi-node distributed training. This feature allows scaling computer vision models across multiple GPUs and servers. This proves valuable for training state-of-the-art models on massive datasets that exceed single-GPU memory limits.
Some of Lambda Labs' key limitations include:
Enterprise focus. Lambda Labs caters to organizations with substantial budgets and complex requirements. Their enterprise support includes custom configurations and dedicated account management, which appeals to research labs and large companies.
Bare-metal approach. Lambda Labs' bare-metal approach eliminates virtualization overhead but comes with much higher costs that price out individual developers and small teams.
From a pricing perspective, Lambda Labs' enterprise positioning translates to premium pricing that often exceeds alternatives by 2-3x. While the hardware performance supports costs for well-funded organizations, most computer vision developers find better value elsewhere.
Bottom line: Lambda Labs serves enterprise-scale computer vision projects requiring dedicated hardware and premium support. However, the major cost difference versus Thunder Compute makes it impractical for budget-conscious developers who can achieve similar results at much lower costs.
4. Vast.ai
Vast.ai operates a peer-to-peer marketplace where individuals and small providers rent out spare GPU capacity. This crowdsourced approach creates a spot market with fluctuating prices based on real-time supply and demand.
Some of Vast.ai's key computer vision features include:
Marketplace. Vast.ai's marketplace model provides access to consumer GPUs like RTX 4090s at attractive hourly rates. For computer vision experiments that don't require enterprise reliability, these consumer cards offer solid performance for tasks like image classification and small-scale object detection training.
Bidding system. The bidding system can yield exceptionally low GPU costs during off-peak periods. Computer vision developers with flexible schedules can take advantage of these price dips for batch processing tasks.
Some of Vast.ai's key limitations include:
Instability. The marketplace structure creates inherent instability. Providers can terminate instances with minimal notice when they need their hardware back or receive higher bids. This unpredictability makes Vast.ai unsuitable for long-running computer vision training jobs that can't tolerate interruptions. Vast.ai's spot market pricing can be attractive, but the risk of sudden termination makes it impractical for serious computer vision development.
Data persistence. This varies by provider, with many offering only ephemeral storage. Computer vision projects involving large datasets face additional complexity managing data across potentially unstable instances.
Bottom line: Vast.ai works for experimental computer vision tasks where cost trumps reliability. However, the service's instability and complexity make Thunder Compute a more practical choice for developers who need dependable infrastructure for production computer vision workflows.
5. Google Cloud
Google Cloud provides GPU instances through Compute Engine with deep integration into their broader cloud ecosystem. The service offers predefined machine configurations with T4, A100, and H100 GPUs alongside managed ML services like Vertex AI.
Some of Google's key computer vision features include:
Ecosystem connectivity. Computer vision projects can use BigQuery for dataset management, Cloud Storage for image repositories, and Vertex AI for model deployment pipelines. This integration makes end-to-end computer vision workflows smoother for teams already using Google services.
Global presence. The global data center presence allows distributed computer vision processing across regions. Teams working with geographically distributed datasets or requiring low-latency inference can benefit from GCP's worldwide infrastructure footprint.
Some of Google's key limitations include:
Enterprise focus. Google Cloud targets enterprise customers requiring compliance certifications and enterprise-grade security. Research shows that large organizations often focus on ecosystem integration over pure cost optimization when selecting cloud GPU providers.
From a pricing perspective, GCP's enterprise positioning translates to premium pricing that often exceeds specialized GPU providers by 3-4x. The assumption is that customers need their entire cloud ecosystem beyond just GPU compute, which doesn't apply to many computer vision developers.
Bottom line: GCP works for enterprise teams already invested in Google Cloud infrastructure but costs much more for standalone GPU access. For computer vision developers focused on cost-effective GPU compute, Thunder Compute offers better value without ecosystem lock-in.
Feature Comparison Table
Here's how the top GPU cloud providers stack up for computer vision projects across the most critical technical specifications and features:
Provider | GPU Types | Memory Options | Deployment Time | VS Code Integration | Persistent Storage | Billing |
|---|---|---|---|---|---|---|
Thunder Compute | T4, A100, H100 | 40GB-80GB | <30 seconds | Native extension | Included | Per-minute |
RunPod | RTX 3090-H100 | 24GB-80GB | 2-5 minutes | Web terminal | Extra cost | Per-second |
Lambda Labs | A100, H100 | 40GB-80GB | 5-10 minutes | SSH only | Included | Hourly |
Vast.ai | RTX 4090-A100 | 24GB-80GB | Variable | SSH only | Provider dependent | Hourly |
Google Cloud | T4, A100, H100 | 16GB-80GB | 10-15 minutes | SSH only | Extra cost | Per-minute |
At the end of the day, Thunder Compute delivers the best combination of low pricing and developer experience. The native VS Code integration removes the SSH complexity that slows down computer vision development cycles on other providers.
Why Thunder Compute is the Best GPU Cloud for Computer Vision
Thunder Compute eliminates the traditional barriers that slow down computer vision development. While other providers force you to choose between affordability and functionality, Thunder Compute delivers both through software-driven optimization that passes savings directly to developers.
At $0.78/hour for A100 80GB instances, Thunder Compute costs less than half of RunPod's $1.64/hour and dramatically undercuts enterprise providers like Lambda Labs at $2.40/hour. This pricing advantage compounds over typical computer vision training cycles that can run for days or weeks.
The hardware swapping feature proves invaluable for computer vision workflows. Start prototyping object detection models on a T4, then upgrade to an H100 for full dataset training without rebuilding your environment or transferring data. And, unlike marketplace providers that can terminate instances unpredictably, Thunder Compute provides stable infrastructure with persistent storage included. Your computer vision datasets and partially trained models remain safe across sessions, preventing costly training interruptions. Thunder Compute combines enterprise-grade hardware with startup-friendly pricing, making advanced computer vision accessible to developers regardless of budget constraints.
But it's the developer experience where Thunder Compute really out performs the competition. Thunder Compute's VS Code integration changes remote GPU development from a painful SSH experience into smooth local-like coding. You can debug computer vision pipelines, visualize training metrics, and manage datasets directly within your familiar development environment.
FAQ
What GPU memory do I need for computer vision training?
Most computer vision models require at least 16GB VRAM for training, with complex object detection and segmentation models needing 40-80GB for large batch sizes. A100 80GB instances handle virtually any computer vision workload, while T4 16GB works for smaller models and inference tasks.
How do I switch between different GPU types during development?
Thunder Compute's hardware swapping feature lets you change GPU specifications with one click while preserving your entire environment. You can start prototyping on a T4 GPU and upgrade to an A100 or H100 for production training without losing your code, data, or installed packages.
Can I pause training jobs to save costs?
Yes, you can stop instances when not actively training and restart them later thanks to persistent storage. Your datasets, partially trained models, and environment state remain intact, allowing you to resume exactly where you left off while avoiding charges for idle time.
What's the difference between prototyping and production modes?
Prototyping mode offers 50% lower costs and is optimized for development and testing workloads with intermittent usage. Production mode provides higher reliability with better uptime SLAs and supports multi-GPU configurations for mission-critical training jobs that require maximum stability.
How quickly can I deploy a computer vision environment?
Thunder Compute instances launch in under 30 seconds with pre-installed CUDA drivers and ML frameworks. The VS Code integration connects immediately without SSH setup, so you can start coding computer vision models within minutes of clicking deploy.
Final thoughts on choosing GPU cloud services for computer vision
Computer vision projects need serious computational power, but you shouldn't have to drain your budget to get it. Thunder Compute makes enterprise-grade GPUs accessible at startup-friendly prices, with the developer tools that actually matter. Your models will train faster, cost less, and you can focus on the work that drives results instead of wrestling with infrastructure. The future of computer vision depends on accessible GPU infrastructure that doesn't force developers to compromise between cost and performance.
Carl Peterson
Try Thunder Compute
Start building AI/ML with the world's cheapest GPUs
Other articles you might like
Learn more about GPUs and more



